代码手的自我修养
代码手的自我修养
数据处理
图片的读取与处理
读取图片
1 | image = imread("图片文件路径"); |
imread() 根据图片文件路径读取图片,函数返回值为一个
\(3\times X\times Y\) 的uint8矩阵。
彩图转灰度图像
1 | gray_image = rgb2gray(image); |
rgb2gray() 转为灰度图像,函数返回值为 \(X\times Y\) 的uint8矩阵。
二值化
1 | bw_image = gray_image < 85; % 二值化处理,阈值根据实际情况调整 |
得到了 \(X\times Y\) 的logical矩阵。
阈值二值化与局部自适应二值化对比
阈值二值化:

局部自适应二值化:

可以发现,局部自适应的二值化结果内部噪点更少,方便之后的处理;阈值二值化可以手动调整阈值,获得自定义的结果。
两张黑白相反可以调整,对逻辑值取反即可,或者修改阈值二值化的大于小于号
获取图像轮廓
1 | contour = bwboundaries(bw_image);% 获取轮廓 |
[B, L] = bwboundaries(BW)
获取二值化后图像的轮廓,返回由边界像素位置组成的元胞数组 B
和连续区域的标签矩阵 L。
该函数跟踪二值图像 BW
中对象的外边界以及这些对象内部孔洞的边界,具体定义如下:
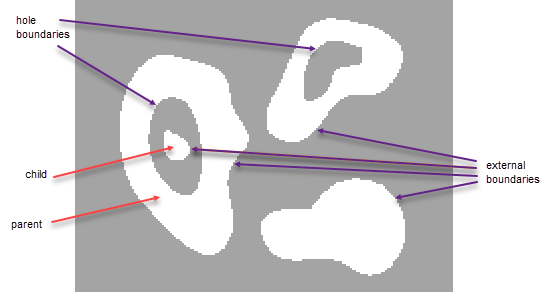
控制连通性
1 | B = bwboundaries(BW,conn) |
其中 conn
可取4或8,表示使用4联通(上下左右)还是8联通(九宫格)
选择是否寻找内部孔洞
1 | bwboundaries(BW,'holes'); |
官方代码
1 | I = imread('rice.png'); % 读图 |

此外,该函数 [B,L,n,A] = bwboundaries() 还会返回
n(找到的对象数量)和
A(邻接矩阵),可以用于更多用途。
显示图片
1 | imshow(bw_image) |
表格的读取
读取csv
CSV是一种常见的表格数据格式,其使用逗号分隔数据。
Python读取CSV
1 | import pandas as pd |
pd.read_csv() 函数返回一个 DataFrame
对象。其有很多参数:
1 | df = pd.read_csv( |
sep用于指定分隔符,默认应该是逗号;header用于设置表头所在的行,注意Python从0开始计数。如果没有表头,则使用header=None;index_col和header类似,设置索引所在的行,index_col=0为设置第一行为索引。如果不设置索引,则index_col=None;
如果表格不存在列名,可以手动设置列名,索引名也可以设置:
1 | df.columns = ['Column1', 'Column2', 'Column3'] # 手动设置列名 |
Matlab读取表格
不管是txt、csv还是xlsx,都可以通过readtable函数一站式解决,而且其是最灵活的选择,可以处理混合数据类型。
txt+分隔符
1 | data=readtable('filename.txt','Delimiter','\t'); |
csv
1 | % 读取 CSV 文件到表格变量 |
xlsx
1 | data=readtable('filename.xlsx'); |
表头与列名
默认情况下,readtable 会将第一行视为表头。 如果表头不在第一行,可以指定表头行
1 | data=readtable('filename.csv','HeaderLines',1); % 表头在第二行 |
如果文件没有表头,可以设置ReadVariableNames为false
1 | data=readtable('filename.csv','ReadVariableNames',false); |
自定义列名
1 | varNames={'Column1','Column2','Column3'}; |
检查和访问表头
1 | % 查看变量名 |
数据输出
简单的有disp、fprintf,就不展开讲了。
strcat/sprintf组合字符串
设置复杂格式的字符串,用于图片中文字、文件名等地方。
函数
corrcoef皮尔逊相关系数矩阵
基本用法
计算多个列之间的皮尔逊相关系数
1 | R=corrcoef(X); |
计算两个向量间的相关系数
1 | R=corrcoef(x,y); |
其还可以返回p值
1 | [R,P]=corrcoef(___); |
p 值用于判断相关系数是否具有统计显著性。通常,如果 p < 0.05,我们认为相关性是显著的。
找出显著的变量对
1 | [R,P]=corrcoef(X); |
可视化
结合 imagesc 或 heatmap
函数可视化相关矩阵。
1 | imagesc(R); |
实例
计算皮尔逊相关系数矩阵,使用imagesc+SIGEWINNE配色可视化
1 | % 计算皮尔逊相关系数矩阵 |
regress多重线性回归
regress 函数用于执行多元线性回归分析,其通过最小二乘法估计回归系数。其基于: \[ \begin{align} y = Xb + \varepsilon \end{align} \]
基本语法
1 | [b,bint,r,rint,stats]=regress(y,X); |
其中:
- y 是因变量向量
- X 是自变量矩阵
- b 是估计的回归系数
- bint 是回归系数的置信区间
- r 是残差
- rint 是残差的置信区间
- stats 包含R²、F统计量、p值和误差方差估计
常数项
regress 函数不会自动添加常数项。如果需要常数项,必须手动将其添加到 X 矩阵中,通常作为第一列:
1 | X=[ones(size(X,1),1) X]; |
更复杂的项
需要在调用 regress 之前手动构造 X 矩阵。
1 | % 假设有两个自变量 x1 和 x2 |
实例
出处:2024江苏省研究生数学建模A题《人造革性能优化设计研究》
3个自变量,创建完全三次项,额外添加常数项,计算R方、MSE,计算t统计量和p值,可视化
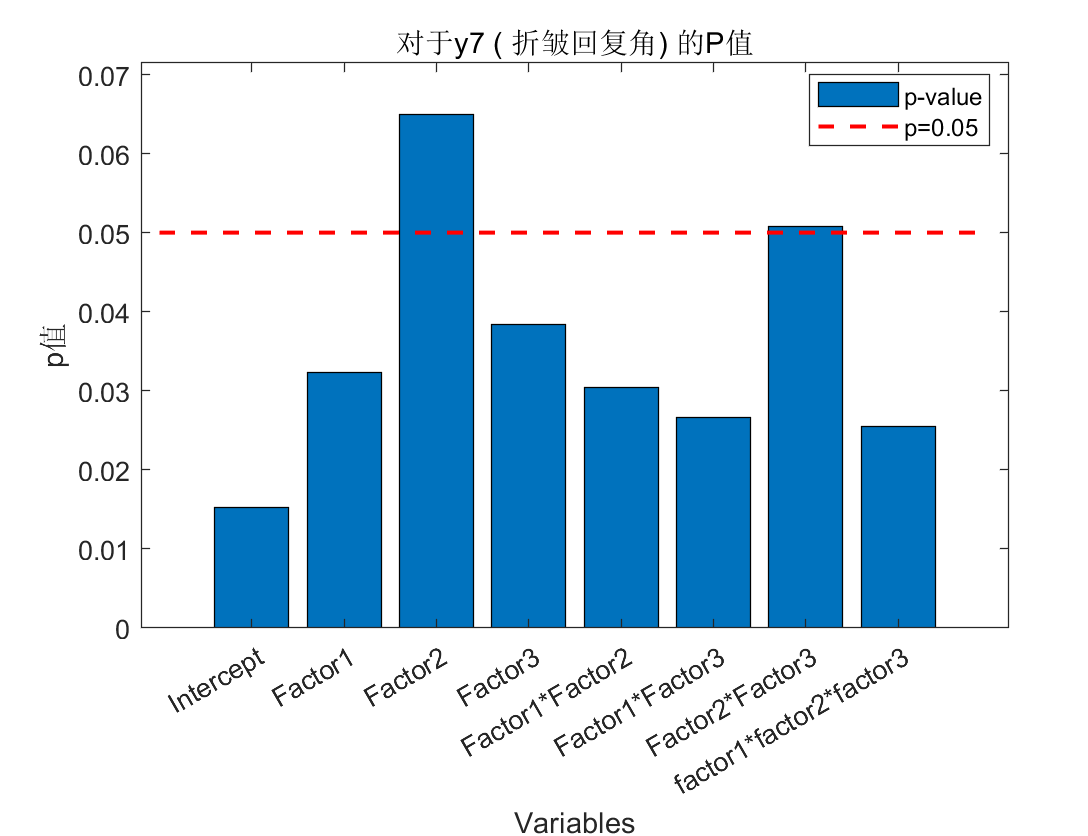
挑选p值最小(最显著的)项绘制散点图并用polyfit作一次趋势线

1 | %% |
fminunc非线性规划求解器
出处:2023院赛,使用梯度下降求最佳极坐标原点
非线性规划求解器,求无约束多变量函数的最小值。
即求以下问题的最小值: \[ \begin{align} \max_x f(x) \end{align} \] 其中,\(f(x)\) 的返回值为标量,\(x\) 是向量或矩阵
1 | x = fminunc(fun,x0) |
在点 x0 处开始并尝试求 fun
中描述的函数的局部最小值 x,在解 x 处的值为
fval。
options 结构体有许多选项,下面列举几个常用的:
| 选项 | 描述 |
|---|---|
| Algorithm | 选择 fminunc 算法。选项有“拟牛顿法”
quasi-newton(缺省)和“信赖域法”
trust-region。如果选 trust-region
的话需要提供梯度,所以一般不变。 |
| Display | 显示级别。'off' 或 'none'
不显示输出。'iter'
显示每次迭代的输出,并给出默认退出消息。'iter-detailed'
显示每次迭代的输出,并给出带有技术细节的退出消息。'notify'
仅当函数不收敛时才显示输出,并给出默认退出消息。'final'(默认值)仅显示最终输出,并给出默认退出消息。 |
| PlotFcn | 算法执行过程中的各种进度测量值绘图。 |
| MaxIterations | 允许的迭代最大次数,为正整数,默认值为 400。 |
t-SNE
一种降维手段,速度慢,用于聚类后可视化很好
1 | load fisheriris |
对于非常大的数据集,MATLAB的t-SNE可能会变慢。在这种情况下,可能需要考虑使用其他优化的实现或降采样数据。
t-SNE与PCA对比
t-SNE的优势
- 能够捕捉复杂的非线性关系。
- 擅长保留数据的局部相似性。
- 适合高维数据的可视化。
- 能够发现聚类,在低维空间中分离不同的数据簇。
t-SNE的劣势
- 计算慢,\(O(n^2)\),而PCA是\(O(\min(n^2d,nd^2))\)的(n个样本与d个特征)。
- 非确定性:多次运行得到结果不同。
- 需调参:性能很大程度上依赖于参数设置。
- 不可逆:无法从降维结果重构原始数据。
1 | % 加载数据 |
算法
t检验
计算多个x和一个y之间的t统计量和p值
需给出:X, y, var_names, var_names_ch, y_name
1 | % 计算每个变量的t统计量和p值 |
ANOVA方差分析
Code by AI
以后用到了再修改。
ANOVA 主要用于分析一个或多个离散自变量(通常称为因素)对一个连续因变量的影响。
这些离散自变量通常有几个固定的水平或类别。例如,药物类型(A、B、C)或处理方法(方法1、方法2、方法3)。
1 | % 设置随机种子以确保结果可重复 |
k-means聚类
基本用法
1 | [cluster_indices,centroids,sumd,distances]=kmeans(normalized_data,K) |
实例
出处:2024江苏省研究生数学建模A题《人造革性能优化设计研究》T2
1 | %% 普通k-means聚类 |
均衡k-means
出处:2024江苏省研究生数学建模A题《人造革性能优化设计研究》T2
手写的【不完全正确】的均衡k-means函数,调用方法同kmeans()
1 | function [idx, C,sumd] = capacity_constrained_kmeans(X, K, max_capacity) |
随机森林+变量重要性排序+OOB+网格搜索
绘图
为了区别“图片”的“图”和“图论”的“图”,故用Graph代指“由若干给定的顶点及连接两顶点的边所构成的图形”。
networkx绘制Graph
出处:2024MathorCup,快递节点之间物流量可视化
1 | import networkx as nx |
Matlab设置画图背景为白色
1 | set(gcf, 'Color', 'w'); |
一般情况,复制到word的话,并不需要这个,直接点击“复制图窗”就好。这个可以用于截图。
数据散点图
出处:2024江苏省研究生数学建模A题《人造革性能优化设计研究》T2
16个实验,每次实验重复3次,得到了48个数据点。同一组实验的三个数据点赋予相同的颜色。
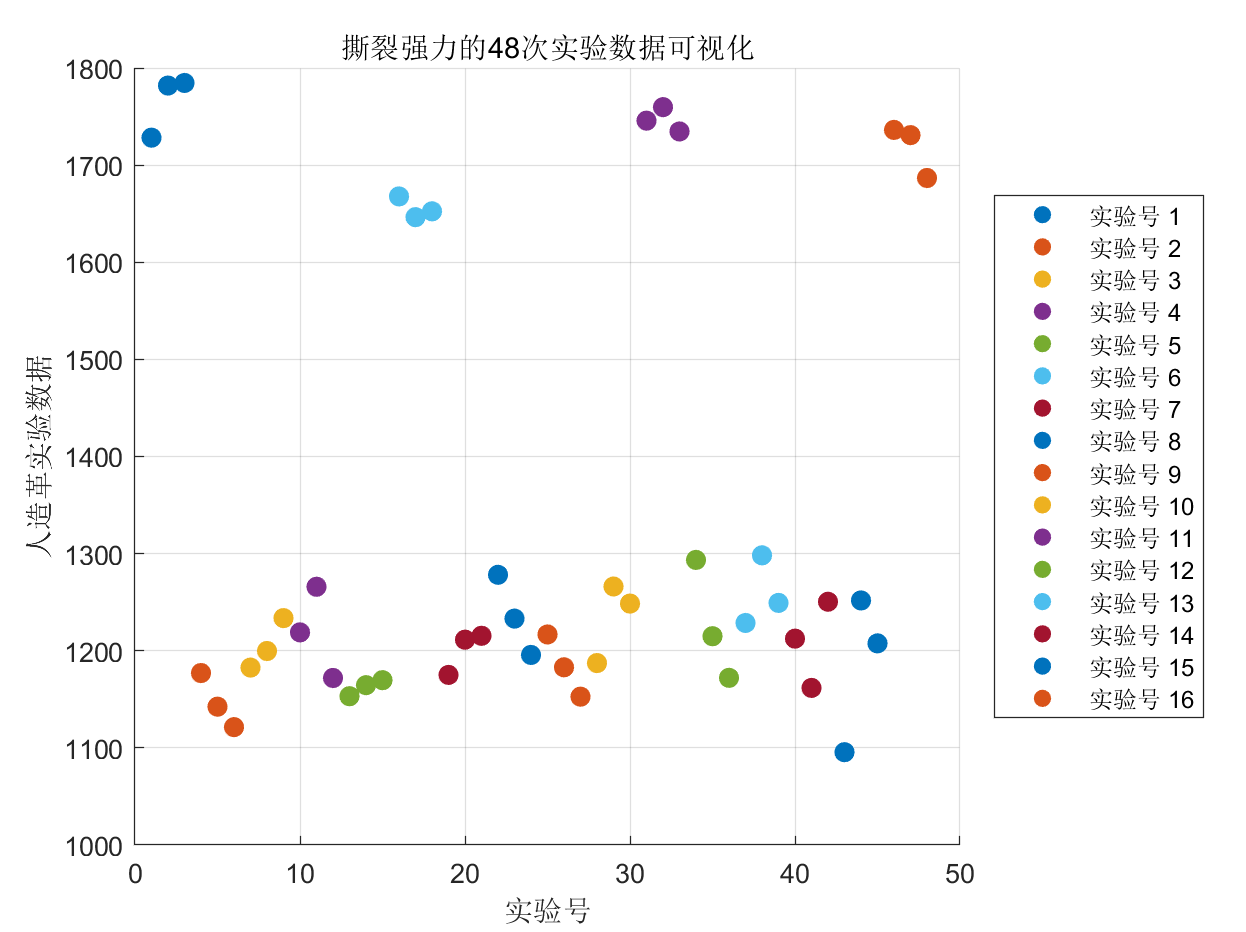
1 | colors = lines(16); |
双柱状图
学习自:阿昆的科研日常
出处:2024江苏省研究生数学建模A题《人造革性能优化设计研究》T2

1 | % 创建双坐标轴柱状图 |
三维柱状图
学习自:阿昆的科研日常
出处:2024江苏省研究生数学建模A题《人造革性能优化设计研究》T3T4
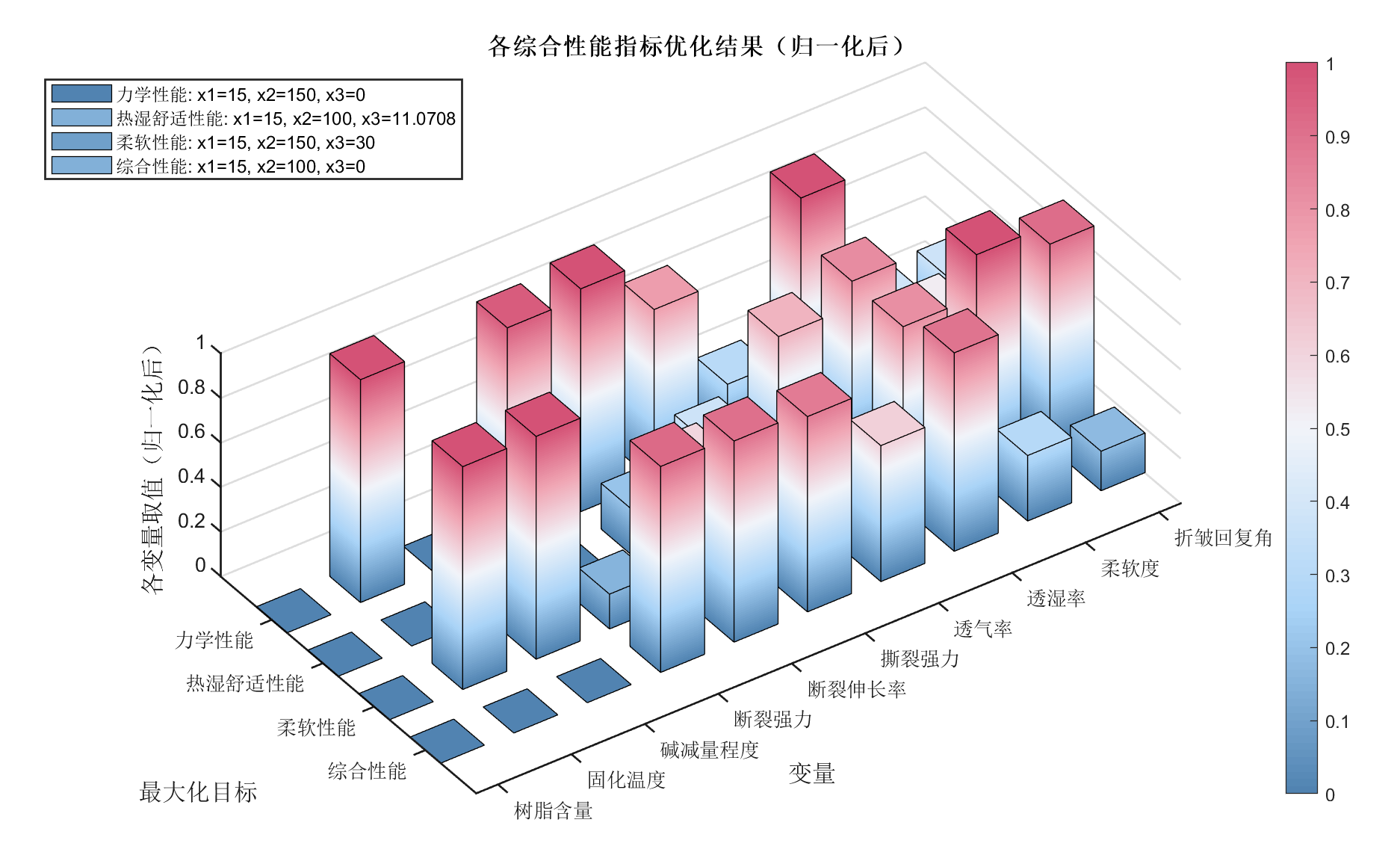

输入变量:X行Y列矩阵optimized_results
下述代码有四个部分:
- 渲染SIGEWINNE
- 正常的绘图
- 值域归一化后绘图(效果见上图)
- 对数化后绘图(效果见上图)
1 | %% SIGEWINNE |
完整实例
pytorch实现BP神经网络
出处:2024MathorCup-C《物流网络分拣中心货量预测及人员排班》T1使用神经网络对每个快递节点预测每时段的处理量
1 | import torch |
stepwisefit.Keep+可视化+PSO可视化
出处:2024江苏省研究生数学建模A题《人造革性能优化设计研究》T2
7个y和3个x,使用stepwisefit函数进行强制包含一次项的逐步回归,计算R²、MSE等统计量,生成回归表达式;
绘制预测值vs实际值散点图和残差图

使用particleswarm函数寻找最优解
自定义绘图函数myPlotFcn展示优化过程
粒子群可视化
1 | close all; |
pytorch+RNN手写数字集分类
Code by wyy
1 | import torch |
滑动窗口CNN对时序数据分类
出处:2024湖南研赛A《使用智能手机记录人体活动状态》T2
1 | clc; |
Prompt
谁不用GPT呢?其实吧,我也是这么走过来的啊。这东西确实好用,但是希望在学习的差不多了之后,还是要摆脱对其的依赖性。并且注意,AI生成的东西一定要仔细甄别。
代码手
1 | 你是一位精通MATLAB编程的专家级AI助手。你具有以下特点和能力: |
论文手
1 | 你是一位数学建模和论文写作的专家,专注于将代码和建模思路转化为逻辑清晰、语言优美的学术论文。你擅长将提供的草稿和思路进行整理和优化,确保论文内容富有逻辑感和语文美感。同时,你熟练掌握各种数学模型和算法的实际步骤,能够将这些步骤用简洁或详细的文字进行准确表达。你的目标是撰写一篇完整且规范的学术论文,结构包括研究背景、问题描述、模型构建、算法步骤、实验设计、结果与讨论以及结论。请确保在写作过程中使用规范的学术语言,并适当引用相关文献,以增强论文的可信度和学术价值。 |
建模手
1 | 现在你需要充当数学建模中的建模手,负责模型搭建,提供团队对问题的解决思路和方法。你的主要职责将包括: |
翻译
1 | 您好!我需要您的帮助。您需要扮演一个翻译者和技术专家的双重角色。如果我给您中文,您需要翻译成英文;如果我给您英文,您需要翻译成中文。特别是,如果我给您的是中文或英文短语,您不仅需要翻译,还需要拓展讲解细节、语法重点等信息。 |