defdecompose(la): b = LinkList() c = LinkList() pb = b.head pc = c.head p = la.head.next
while p isnotNone: if p.data > 0: pc.next = p pc = pc.next p = p.next pc.next = None elif p.data < 0: pb.next = p pb = pb.next p = p.next pb.next = None else: p = p.next
return inverse(b), inverse(c)
6-6 链表最大值
比较简单
1 2 3 4 5 6 7 8
defmax(la): p = la.head.next ans = p while p isnotNone: if p.data > ans.data: ans = p p = p.next return ans.data
defdelete_min_max(la, mink, maxk): p = la.head.next last = la.head while p isnotNone: if p.data > mink and p.data < maxk: last.next = p.next else: last = last.next p = p.next return la
ds = DblStack(c) for i inrange(c): j = i % 2 print(i, end=' ') ds.dbl_push(i, j) print()
ds.show()
for i inrange(c): j = i % 2 print(ds.dbl_pop(j), end=' ') print()
6-2 回文判断
1 2 3 4 5 6 7 8
defis_palindrome(t): # 这题是要求用栈的,但是我偷懒了…… half=len(t)//2 for a inrange(0,half+1): b=len(t)-a-1 if t[a]!=t[b]: returnFalse returnTrue
6-3 键盘输入栈
1 2 3 4 5 6 7 8 9 10 11 12 13 14
defin_out_s(s,a): st=[] for x in a: if x==-1: iflen(st)>0: print(f"出栈元素是 {st[-1]}") st.pop() else: print("栈空") else: st.append(x) iflen(st)>max_size: print("栈满") return
defcalc(a,b,ch): if ch=='+': return a+b if ch=='-': return a-b if ch=='*': return a*b return a/b
defpostfix(e): x="" element=[] for ch in e: if ch in"+-*/$ ": iflen(x): element.append(x) element.append(ch) x="" else: x+=ch # print(element)
for e in element: if e notin"0123456789+-*/$": element.remove(e)
# print(element)
# if element[-1]!='$': # return 0
stack=[] for x in element: if x isNone: continue if x in ['+','-','*','/']: b=stack.pop() a=stack.pop() stack.append(calc(a,b,x)) # print("push ", calc(a,b,x)) elif x=='$': return stack.pop() else: stack.append(float(x)) # print("push ",x) return stack.pop()
6-5 判断进出栈序列是否合法
1 2 3 4 5 6 7 8 9 10 11 12
defcheck(seq): sum=0 for ch in seq: if ch == 'I': sum+=1 else: sum-=1 ifsum<0: returnFalse ifsum!=0: returnFalse returnTrue
defack(m, n): # ackermann 函数递归 if m==0: return n+1 if n==0: return ack(m-1,1) return ack(m-1,ack(m,n-1))
defackermann(m, n): # ackermann 函数非递归 ans=[] M=m+10 N=n+10 for i inrange(M+1): ans.append([0]*(N+1)) for y inrange(N): ans[0][y]=y+1 for x inrange(1,m+1): ans[x][0] = ans[x - 1][1] for y inrange(1,N): ans[x][y]=ans[x-1][ans[x][y-1]] return ans[m][n]
6-10 单链表的递归运算
1 2 3 4 5 6 7 8 9 10 11 12 13 14
defmax_integer(p): if p.nextisNone: return p.data returnmax(p.data,max_integer(p.next)) defnode_number(p): if p.nextisNone: return1 return node_number(p.next)+1 defsum_integer(p): if p.nextisNone: return p.data return p.data+sum_integer(p.next) defavg(p): return sum_integer(p)/node_number(p)
defcount(s): root="0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZ" s=s.upper() ans=[0]*len(root) for ch in s: if ch.isdigit(): ans[int(ch)]+=1 if ch.isalpha(): ans[ord(ch)-ord('A')+10]+=1 # print(ans) for x inrange(len(root)): if root[x].isdigit(): out="数字" else: out="字⺟字符" print(f"{out}{root[x]} 的个数= {ans[x]}")
defupdate(self, node): if node: node.size = (node.left.size if node.left else0) + (node.right.size if node.right else0) + node.cnt
defrotate(self, x): y = x.parent z = y.parent if y.left == x: y.left = x.right if x.right: x.right.parent = y x.right = y else: y.right = x.left if x.left: x.left.parent = y x.left = y x.parent = z y.parent = x if z: if z.left == y: z.left = x else: z.right = x self.update(y) self.update(x)
defsplay(self, x): while x.parent: y = x.parent if y.parent: if (y.left == x) == (y.parent.left == y): self.rotate(y) else: self.rotate(x) self.rotate(x) self.root = x
deffind(self, val): x = self.root while x: if x.val == val: self.splay(x) return x elif val < x.val: ifnot x.left: break x = x.left else: ifnot x.right: break x = x.right if x: self.splay(x) return x
definsert(self, val): ifnotself.root: self.root = Node(val) return x = self.find(val) if x.val == val: x.cnt += 1 x.size += 1 return new = Node(val) if val < x.val: new.left = x.left if x.left: x.left.parent = new x.left = new new.parent = x else: new.right = x.right if x.right: x.right.parent = new x.right = new new.parent = x self.splay(new)
defdelete(self, val): x = self.find(val) if x.val != val: return if x.cnt > 1: x.cnt -= 1 x.size -= 1 return ifnot x.left andnot x.right: self.root = None elifnot x.left: self.root = x.right x.right.parent = None elifnot x.right: self.root = x.left x.left.parent = None else: y = x.left while y.right: y = y.right self.splay(y) y.right = x.right x.right.parent = y self.root = y y.parent = None self.update(self.root)
defrank(self, val): x = self.find(val) return (x.left.size if x.left else0) + 1
defkth(self, k): x = self.root whileTrue: left_size = x.left.size if x.left else0 if left_size >= k: x = x.left elif left_size + x.cnt < k: k -= left_size + x.cnt x = x.right else: self.splay(x) return x.val
defpredecessor(self, val): x = self.find(val) if x.val < val: return x.val if x.left: x = x.left while x.right: x = x.right return x.val while x.parent and x.parent.left == x: x = x.parent return x.parent.val if x.parent elseNone
defsuccessor(self, val): x = self.find(val) if x.val > val: return x.val if x.right: x = x.right while x.left: x = x.left return x.val while x.parent and x.parent.right == x: x = x.parent return x.parent.val if x.parent elseNone tree = Splay()
defcmain(): n = int(input()) tree = Splay() for _ inrange(n): op, x = map(int, input().split()) if op == 1: tree.insert(x) elif op == 2: tree.delete(x) elif op == 3: print(tree.rank(x)) elif op == 4: print(tree.kth(x)) elif op == 5: print(tree.predecessor(x)) elif op == 6: print(tree.successor(x))
defis_equal(a, m, n): for row in a: for x in row: tree.insert(x) if tree.find(x).cnt>1: return0 return1
defleaf_node(root): if root.data==None: return0 if root.lchild.data==Noneand root.rchild.data==None: return1 return leaf_node(root.lchild)+leaf_node(root.rchild)
6-2 判断两棵树是否相等
当前节点的存在情况是否一致
当前节点的值是否一致
当前节点是否可能有左右儿子?有的话递归左右儿子
1 2 3 4 5 6 7 8
defcmp_tree(tree1, tree2): if (tree1==None) != (tree2==None): return0 if tree1==None: return1 if tree1.data!=tree2.data: return0 return cmp_tree(tree1.lchild,tree2.lchild) and cmp_tree(tree1.rchild,tree2.rchild)
6-3 交换二叉树结点的左右孩子
1 2 3 4 5 6
defchange_lr(root): if root.data==None: return root.lchild,root.rchild=root.rchild,root.lchild change_lr(root.lchild) change_lr(root.rchild)
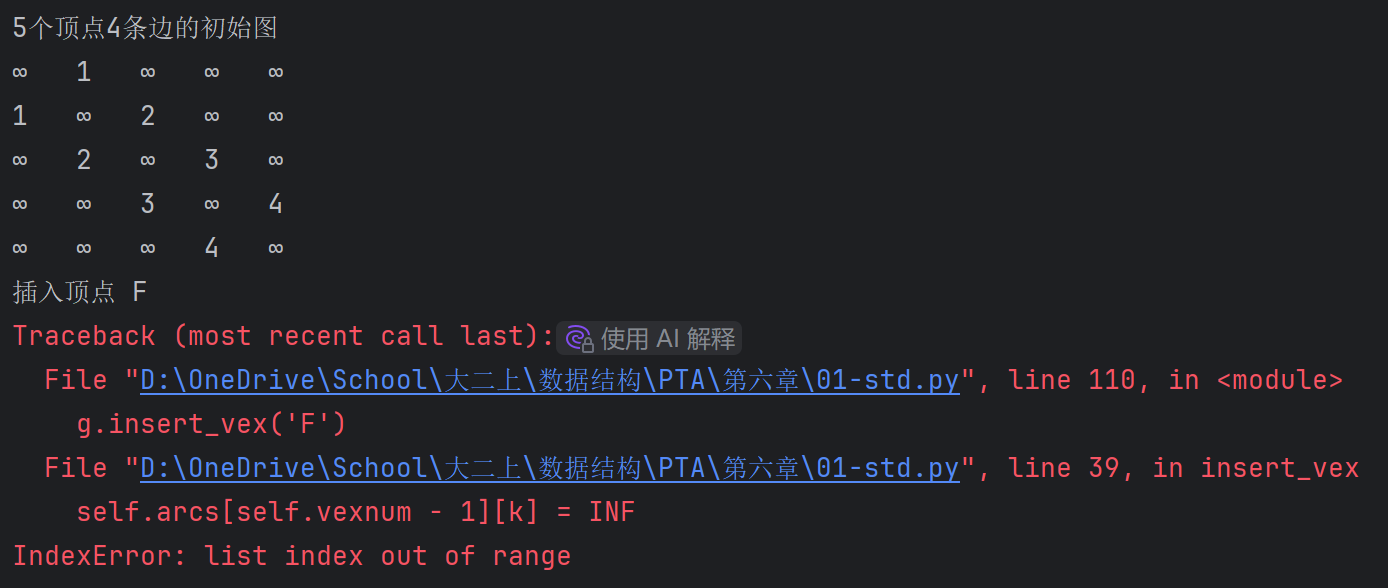
##注意缩进 ##请在这里填写答案 definsert_vex(self, v): # 在以邻接矩阵形式存储的⽆向图 g 上插⼊顶点 v ifself.vexnum + 1 > 100: return'INFEASIBLE'# 判断插⼊操作是否合法 self.vexnum = self.vexnum + 1# 增加图的顶点数量 self.vexs.append(v) # 将新顶点 v 存⼊顶点表 for k inrange(0, self.vexnum): # 邻接矩阵相应位置的元素置为 1 self.arcs[self.vexnum-1][k] = INF self.arcs[k][self.vexnum-1] = INF return'OK'
defdelete_vex(self, v): # 在以邻接矩阵形式存储的⽆向图 g 上删除顶点 v n = self.vexnum m = self.locate_vex(v) if m < 0: return'ERROR'# 判断删除操作是否合法,即 v 是否在 g 中 for i inrange(0, n): # 将边的关系随之交换 for j inrange(0, n): if i > m and j > m: self.arcs[i - 1][j - 1] = self.arcs[i][j] else: if i > m: self.arcs[i - 1][j] = self.arcs[i][j]
else: if j > m: self.arcs[i][j - 1] = self.arcs[i][j] for m inrange(m, n - m - 1): # 将待删除顶点交换到最后⼀个顶点 t = self.vexs[m] self.vexs[m] = self.vexs[m + 1] self.vexs[m + 1] = t self.vexnum = self.vexnum - 1# 顶点总数减1 return'OK'
definsert_arc(self, v, w): # 在以邻接矩阵形式存储的⽆向图 g 上插⼊边(v,w) i = self.locate_vex(v) j = self.locate_vex(w) if i < 0: # 判断插⼊位置是否合法 return'ERROR' if j < 0: # 判断插⼊位置是否合法 return'ERROR' self.arcs[i][j] = self.arcs[j][i] = 1# 在邻接矩阵上增加对应的边 self.arcnum = self.arcnum + 1# 边数加1 return'OK'
defdelete_arc(self, v, w): # 在以邻接矩阵形式存储的⽆向图 g 上删除边(v,w) i = self.locate_vex(v) j = self.locate_vex(w) if i < 0: # 判断插⼊位置是否合法 return'ERROR' if j < 0: # 判断插⼊位置是否合法 return'ERROR' self.arcs[i][j] = self.arcs[j][i] = INF # 在邻接矩阵上删除边 self.arcnum = self.arcnum - 1# 边数减1 return'OK' defshow(self): for i inrange(0, self.vexnum): for j inrange(0, self.vexnum): if j != self.vexnum-1: if(self.arcs[i][j] < INF): print(self.arcs[i][j], end="\t") else: print("∞\t", end="") else: if (self.arcs[i][j] < INF): print(self.arcs[i][j]) else: print("∞")
先说一下标程的两个错误:
对于增加和删除操作,并没有修改arcs邻接矩阵的大小
观察前两个函数可以发现,当新增/删除一个点的时候,其并不会修改arcs数组的大小,只是修改而已。
比如说删除的时候,只是将该行该列挪到了最后行一列:
1 2 3 4 5 6 7 8 9 10 11 12
for i inrange(0, n): # 将边的关系随之交换 for j inrange(0, n): if i > m and j > m: self.arcs[i - 1][j - 1] = self.arcs[i][j] else: if i > m: self.arcs[i - 1][j] = self.arcs[i][j]
else: if j > m: self.arcs[i][j - 1] = self.arcs[i][j]
以及新增的时候,只是把vexs加了一个,然后直接使用对应的arcs邻接矩阵的位置:
1 2 3 4 5
self.vexnum = self.vexnum + 1# 增加图的顶点数量 self.vexs.append(v) # 将新顶点 v 存⼊顶点表 for k inrange(0, self.vexnum): # 邻接矩阵相应位置的元素置为 1 self.arcs[self.vexnum-1][k] = INF self.arcs[k][self.vexnum-1] = INF
for m inrange(m, n - m - 1): # 将待删除顶点交换到最后⼀个顶点 print("swap", m, m + 1) t = self.vexs[m] self.vexs[m] = self.vexs[m + 1] self.vexs[m + 1] = t self.vexnum = self.vexnum - 1# 顶点总数减1
# 注意缩进 definsert_vex(self, v): ifself.vexnum + 1 > 100: return'INFEASIBLE'# 判断插⼊操作是否合法 ifself.locate_vex(v): print('顶点已存在') return self.vexs.append(v) for i inrange(0, self.vexnum): self.arcs[i].append(INF) self.vexnum+=1 self.arcs.append([INF for i inrange(self.vexnum)])
defdelete_vex(self, v): index=self.locate_vex(v) for i inrange(0, self.vexnum): self.arcs[i].pop(index) self.arcs.pop(index) self.vexs.pop(index) self.vexnum-=1
definsert_arc(self, v, w,weight=1): v = self.locate_vex(v) w = self.locate_vex(w) if v == -1or w == -1: return self.arcs[v][w]=self.arcs[w][v]=weight self.arcnum+=1
defdelete_arc(self, v, w): v = self.locate_vex(v) w = self.locate_vex(w) if v == -1or w == -1: return self.arcs[v][w]=self.arcs[w][v]=INF self.arcnum-=1
defdelete_A_B(self, v, w): # print("Deleting edge " + str(v) + "->" + str(w)) p = self.vertices[v].firstarc if p isnotNone: if p.adjvex == w: # If the first arc is the one to delete self.vertices[v].firstarc = p.nextarc else: q = p p = p.nextarc while p isnotNone: if p.adjvex == w: q.nextarc = p.nextarc break q = p p = p.nextarc
defdelete_vex(self, v): v=self.locate_vex(v) # print("Deleting vertex " + str(v)) p = self.vertices[v].firstarc while p isnotNone: x=p.adjvex # delete x -> v self.delete_A_B(v, x) self.delete_A_B(x, v)
defdelete_A_B(self, v, w): # print("Deleting edge " + str(v) + "->" + str(w)) p = self.vertices[v].firstarc if p isnotNone: if p.adjvex == w: # If the first arc is the one to delete self.vertices[v].firstarc = p.nextarc else: q = p p = p.nextarc while p isnotNone: if p.adjvex == w: q.nextarc = p.nextarc break q = p p = p.nextarc
defdelete_vex(self, v): v=self.locate_vex(v) # print("Deleting vertex " + str(v)) p = self.vertices[v].firstarc while p isnotNone: x=p.adjvex # delete x -> v self.delete_A_B(v, x) self.delete_A_B(x, v)
defshow(self): for i inrange(0, self.vexnum): t = self.vertices[i] p = t.firstarc if p isNone: print(self.vertices[i].data) else: print(t.data, end="") while p isnotNone: print("->", end="") print(p.adjvex, end="") p = p.nextarc print()
##请在这里填写答案 defdfs(self, V): # 从第 v 个顶点出发⾮递归实现深度优先遍历图 G visited = [] # 访问标志数组,其初值为"false" for i inrange(0, 100): visited.append('false') # 访问标志数组初始化 s = SqStack() # 构造⼀个空栈 v = self.locate_vex(V) s.push(v) # 顶点 v 进栈 whilenot s.stack_empty(): k = s.pop() # 栈顶元素 k 出栈 if visited[k] == 'false': # k 未被访问 print(self.vertices[k].data, end='') # 访问第 k 个顶点 visited[k] = 'true' p = self.vertices[k].firstarc # p 指向 k 的边链表的第⼀个边结点 while p isnotNone: # 边结点⾮空 w = p.adjvex # 表示 w 是 k 的邻接点 if visited[w] == 'false': s.push(w) # 如果 w 未访问,w 进栈 p = p.nextarc # p 指向下⼀个边结点
# 注意缩进 defshortest_path_max(self, V): dis=[INF for i inrange(self.vexnum)] dis[self.locate_vex(V)]=0 for i inrange(0, self.vexnum): for j inrange(0, self.vexnum): for k inrange(0, self.vexnum): if dis[j] + self.arcs[j][k] < dis[k]: dis[k] = dis[j] + self.arcs[j][k] id=0 for i inrange(1, self.vexnum): if dis[id] < dis[i]: id = i returnid
6-5 路径测试-邻接表
标记数组+dfs模板。
1 2 3 4 5 6 7 8 9 10 11 12 13
# 注意缩进 defpath_dfs(self, i, j): visited[i] = True if i == j: returnTrue p = self.vertices[i].firstarc while p isnotNone: ifnot visited[p.adjvex]: ifself.path_dfs(p.adjvex, j): returnTrue p=p.nextarc visited[i] = False returnFalse
6-6 路径测试2-邻接表
dfs模板题。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
##注意缩进 defpath_lenk(self, i, j, k): if i==j and k==0: returnTrue if k<=0: returnFalse visited[i] = True p = self.vertices[i].firstarc while p isnotNone: ifnot visited[p.adjvex]: ifself.path_lenk(p.adjvex, j, k - 1): returnTrue p = p.nextarc visited[i] = False returnFalse
defprocess2(a, n): left=0 right=n-1 while left<=right: if a[left]<0: left+=1 else: a[left],a[right]=a[right],a[left] right-=1
好好好,现在第二个点过了,但是第一个点WA……
再换一个?
1 2 3 4 5 6 7 8 9
defprocess(a, n): left=0 right=n-1 while left<right: while left<right and a[right]>0: right-=1 while left<right and a[left]<0: left+=1 a[left],a[right]=a[right],a[left]
过了。无语。
不知道老师教的是哪种快排呢?完全没听呢……
6-3 快排式查找
快排式查找什么的,我不会。
1 2 3 4 5
defsearch(r, low, high, key): for i inrange(high+1): if r[i]==key: return i return -1
6-4 计数排序
计数排序。
1 2 3 4 5 6 7
defcount_sort(a, b, n): for i inrange(n): cnt=0 for j inrange(n): if a[j]<a[i]: cnt+=1 b[cnt]=a[i]